我们知道,Java NIO的ByteBuffer只有一个position指针标识位置,读写切换时需要调用flip()方法,这样容易出错。而Netty为了解决这个问题,使用了两个指针readerIndex、writerIndex。当然,Netty的ByteBuf的功能不仅仅如此,让我们一起看看Netty的ButeBuf设计。
一、ByteBuf设计原理
1. 读写指针设计
ByteBuf通过两个指针协助缓冲区的读写操作,读操作用readerIndex,写操作用writerIndex。
readerIndex和writerIndex初始值都是0,随着写入writerIndex会增加,同样的,随着读取readerIndex会增加,但是readerIndex不能大于writerInder。
当读取了一定数据后,0 ~ readerIndex之间就被视为discard的,调用discardReadByte 方法,可以释放这段空间,令readerIndex = 0,writerIndex = writerIndex - discard。
这样的设计导致读写互不干扰,读写切换不再需要调整位置指针,极大的简化了缓冲区读写操作。
2. 扩容设计
我们知道,Java NIO的ByteBuffer底层是数组,它本身并不提供扩容操作,如果缓冲区剩余可写空间不足,就会发生BufferOverflowExeption。
public ByteBuffer put(byte[] src, int offset, int length) { checkBounds(offset, length, src.length); // 所有的put操作都有这个校验,可用空间不足直接抛异常 if (length > remaining()) throw new BufferOverflowException(); int end = offset + length; for (int i = offset; i < end; i++) this.put(src[i]); return this;}public final int remaining() { return limit - position;} 为了避免这个问题,需要在put操作时先对剩余可用空间校验,如果剩余空间不足,需要自己创建新的ByteBuffer,并将之前的ByteBuffer copy过来,这样对使用者很不友善。而Netty的ByteBuffer对write操作进行了封装,由Netty做缓冲区剩余空间校验,如果可用缓冲区不足,ByteBuf会自动进行动态扩展。
二、ByteBuf主要继承关系
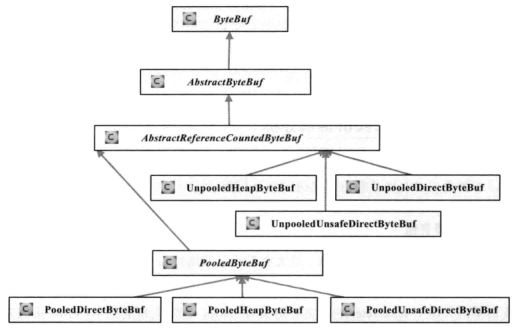
从内存分配角度来看,ByteBuf分为两类:
1)堆内存字节缓冲区:在堆内存中分配,可以被JVM自动回收,但是在进行Socket的IO读写时,需要多做一次内存复制(堆内存中的缓冲区复制到内核Channel中),性能会有所下降。
2)直接内存字节缓冲区:在堆外进行内存分配,需要自己分配内存及回收,但是它在写入或从Socket Channel中读取时,少一次内存复制,性能比堆内存字节缓冲区要高。
tips:在IO通讯的读写缓冲区使用直接内存字节缓冲区,在后端业务消息编解码模块中使用堆内存字节缓冲区,可以使性能达到最优。
从内存回收的角度来看,ByteBuf也分为两类:
1)基于对象池的ByteBuf,它的特点就是可以重用ByteBuf。基于对象池的ByteBuf自己维护了一个内存池,可以循环利用创建的ByteBuf,提升内存使用效率。
2)普通的ByteBuf,不能重用,每次都要新创建一个ByteBuf。
三、AbstractByteBuf
1. 成员变量
// 用于检测对象是否泄漏 static final ResourceLeakDetectorleakDetector = new ResourceLeakDetector (ByteBuf.class); // 读操做 和 写操作 的位置指针 int readerIndex; private int writerIndex; // 读操作 和 写操作 的标记,可以通过reset()回到标记的地方 private int markedReaderIndex; private int markedWriterIndex; // 最大容量 private int maxCapacity; // private SwappedByteBuf swappedBuf;
2. 读操作
首先检查入参,如果要读的数据长度小于0,说明参数传错了,抛IllegalArgumentException异常;如果要读的数据长度大于可读数据长度,抛IndexOutOfBoundsException。
校验通过后,进行读操作,这个由子类实现。
最后,调整readerIndex指针。
public ByteBuf readBytes(byte[] dst, int dstIndex, int length) { checkReadableBytes(length); // 由子类实现 getBytes(readerIndex, dst, dstIndex, length); readerIndex += length; return this; } protected final void checkReadableBytes(int minimumReadableBytes) { ensureAccessible(); if (minimumReadableBytes < 0) { throw new IllegalArgumentException("minimumReadableBytes: " + minimumReadableBytes + " (expected: >= 0)"); } if (readerIndex > writerIndex - minimumReadableBytes) { throw new IndexOutOfBoundsException(String.format( "readerIndex(%d) + length(%d) exceeds writerIndex(%d): %s", readerIndex, minimumReadableBytes, writerIndex, this)); } } 3. 写操作
首先做数据校验及缓冲区可用性校验。
如果可用缓冲区容量不足以放下整个byte数组,则需要扩容。扩容时需要先计算新的ByteBuf容量并创建,然后将老的ByteBuf复制到新的ByteBuf中。
最后才是写操作。
public ByteBuf writeBytes(byte[] src, int srcIndex, int length) { // 数据校验及扩容 ensureWritable(length); // 由子类实现 setBytes(writerIndex, src, srcIndex, length); writerIndex += length; return this; } public ByteBuf ensureWritable(int minWritableBytes) { // 校验入参 if (minWritableBytes < 0) { throw new IllegalArgumentException(String.format( "minWritableBytes: %d (expected: >= 0)", minWritableBytes)); } // 如果可写长度大于待写长度,直接写即可 if (minWritableBytes <= writableBytes()) { return this; } // 如果待写长度大于最多可写长度(扩容也没法满足),直接抛异常 if (minWritableBytes > maxCapacity - writerIndex) { throw new IndexOutOfBoundsException(String.format( "writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s", writerIndex, minWritableBytes, maxCapacity, this)); } // 计算新的ByteBuf的容量(找一个合适的新容量) int newCapacity = calculateNewCapacity(writerIndex + minWritableBytes); // 重建新的缓冲区,并将老的缓冲区的数据copy过去,交给子类实现 capacity(newCapacity); return this; } private int calculateNewCapacity(int minNewCapacity) { final int maxCapacity = this.maxCapacity; final int threshold = 1048576 * 4; // 步长4MB if (minNewCapacity == threshold) { return threshold; } // If over threshold, do not double but just increase by threshold. if (minNewCapacity > threshold) { int newCapacity = minNewCapacity / threshold * threshold;//让它成为4MB的整数倍 if (newCapacity > maxCapacity - threshold) { newCapacity = maxCapacity; } else { newCapacity += threshold; } return newCapacity; } // 比4MB小,采用64K步进的方式扩容,避免内存浪费 int newCapacity = 64; while (newCapacity < minNewCapacity) { newCapacity <<= 1; } return Math.min(newCapacity, maxCapacity); } 4. 释放已读缓冲区
前面说到,0 ~ readerIndex之间的数据已读取过,这一段被视为discard的,我们可以调用discardReadBytes()方法,释放这部分缓冲区,达到缓冲区重用的目的。
但是,discardReadBytes()方法原理是数组拷贝,在执行这个方法时你需要先判断是否值得这样做。
public ByteBuf discardReadBytes() { ensureAccessible(); // 如果等于0,说明没有可释放缓冲区 if (readerIndex == 0) { return this; } if (readerIndex != writerIndex) { // 子类实现 setBytes(0, this, readerIndex, writerIndex - readerIndex); writerIndex -= readerIndex; // 同时调整markReaderIndex和markWriterIndex adjustMarkers(readerIndex); readerIndex = 0; } else { adjustMarkers(readerIndex); writerIndex = readerIndex = 0; } return this; } protected final void adjustMarkers(int decrement) { int markedReaderIndex = this.markedReaderIndex; if (markedReaderIndex <= decrement) { this.markedReaderIndex = 0; int markedWriterIndex = this.markedWriterIndex; if (markedWriterIndex <= decrement) { this.markedWriterIndex = 0; } else { this.markedWriterIndex = markedWriterIndex - decrement; } } else { this.markedReaderIndex = markedReaderIndex - decrement; markedWriterIndex -= decrement; } } 5. skipBytes(..)
在解码的时候,有时需要丢弃非法数据包,获取跳过不需要读取的字节码,此时可以使用skipByte(..)方法,忽略指定长度的字节数组。
public ByteBuf skipBytes(int length) { // 校验入参 checkReadableBytes(length); int newReaderIndex = readerIndex + length; if (newReaderIndex > writerIndex) { throw new IndexOutOfBoundsException(String.format( "length: %d (expected: readerIndex(%d) + length <= writerIndex(%d))", length, readerIndex, writerIndex)); } readerIndex = newReaderIndex; return this; } 四、AbstractReferenceCountedByteBuf
从名字可以看出,这个类的作用主要是对ButeBuf引用进行计数,用于跟踪对象的分配及销毁。
1. 成员变量
// 并发包中的类,对 AbstractReferenceCountedByteBuf 中的 refCnt,进行原子化操作 private static final AtomicIntegerFieldUpdaterrefCntUpdater = AtomicIntegerFieldUpdater.newUpdater(AbstractReferenceCountedByteBuf.class, "refCnt"); // refCnt的偏移量,也就是 refCnt 在AbstractReferenceCountedByteBuf中的内存地址 private static final long REFCNT_FIELD_OFFSET; static { long refCntFieldOffset = -1; try { if (PlatformDependent.hasUnsafe()) { refCntFieldOffset = PlatformDependent.objectFieldOffset( AbstractReferenceCountedByteBuf.class.getDeclaredField("refCnt")); } } catch (Throwable t) { // Ignored } REFCNT_FIELD_OFFSET = refCntFieldOffset; } //对象引用次数 @SuppressWarnings("FieldMayBeFinal") private volatile int refCnt = 1;
2. 对象引用计数器
每调用一次 retain() 方法,引用计数器就加1。
由于 refCnt 初始值为1,每次申请加1,释放减1,当申请数等于释放数时,对象被回收,故 refCnt 不可能为0。如果为0,说明对象被错误、意外的引用了,抛出异常。
如果引用计数器达到整形最大值,则直接抛异常,除非是恶意破坏,否则不会出现这种情况吧。
最后就是对 refCnt 做原子性的 cas 操作。
public ByteBuf retain() { for (;;) { int refCnt = this.refCnt; if (refCnt == 0) { throw new IllegalReferenceCountException(0, 1); } if (refCnt == Integer.MAX_VALUE) { throw new IllegalReferenceCountException(Integer.MAX_VALUE, 1); } if (refCntUpdater.compareAndSet(this, refCnt, refCnt + 1)) { break; } } return this; } 有增必有减,我们看一下 refCnt 减少的代码。
当对象被释放时,refCnt 减1,当减到 1 时,说明申请数等于释放数,需要将该对象回收掉。
public final boolean release() { for (;;) { int refCnt = this.refCnt; if (refCnt == 0) { throw new IllegalReferenceCountException(0, -1); } if (refCntUpdater.compareAndSet(this, refCnt, refCnt - 1)) { if (refCnt == 1) { // 垃圾回收 deallocate(); return true; } return false; } } } 五、UnpooledHeapByteBuf
前面的ByteBuf分类描述,我们可以判断,UnpooledHeapByteBuf 就是普通的堆内存ByteBuf,没有内存池,没有堆外内存,使用起来更不容易出现内存管理方面的问题。
1. 成员变量
// 用于UnpooledHeapByteBuf内存分配 private final ByteBufAllocator alloc; // 缓冲区 private byte[] array; // Java NIO的ByteBuffer,用于Netty的ByteBuf到NIO的ByteBuffer转换 private ByteBuffer tmpNioBuf;
2. 动态扩展缓冲区
在 AbstractByteBuf 中我们提到,动态扩展缓冲区的操作是交给子类完成的,这里我们看一下 UnpooledHeapByteBuf 是怎么做的。
首先对新的byte数组做校验,然后进行ByteBuf重建。
这里分为三种情况,
1)newCapacity > oldCapacity,直接创建一个新数组,拷贝过去就行了
2)newCapacity == oldCapacity,不做处理
3)newCapacity < oldCapacity,先判断readerIndex,如果readerIndex大于等于newCapacity,说明没有数据需要复制到缓冲区,直接设置readerIndex和writerIndex的值为newCapacity即可;当readerIndex小于newCapacity时,readerIndex到writerIndex之间的数据需要复制到新的byte数组,这个时候,如果writerIndex - readerIndex > newCapacity,就会发生数组下标越界,为了防止越界,当writerIndex > newCapacity时,令writerIndex = newCapacity,然后做 byte 数组赋值操作。最后,替换掉ByteBuf中持有的 byte数组引用,并令NIO 的 ByteBuffer为 null。
public ByteBuf capacity(int newCapacity) { ensureAccessible(); // 1. 对入参做合法性校验 if (newCapacity < 0 || newCapacity > maxCapacity()) { throw new IllegalArgumentException("newCapacity: " + newCapacity); } int oldCapacity = array.length; if (newCapacity > oldCapacity) { // 2. byte数组copy,然后替换掉原来的byte数组 byte[] newArray = new byte[newCapacity]; System.arraycopy(array, 0, newArray, 0, array.length); setArray(newArray); } else if (newCapacity < oldCapacity) { // 如果新容量小于老容量,则不需要动态扩展,但是需要截取当前缓冲区创建一个新的子缓冲区 byte[] newArray = new byte[newCapacity]; int readerIndex = readerIndex(); if (readerIndex < newCapacity) { int writerIndex = writerIndex(); if (writerIndex > newCapacity) { // 如果writerIndex大于newCapacity,则有可能发生越界,这里直接截断 writerIndex(writerIndex = newCapacity); } System.arraycopy(array, readerIndex, newArray, readerIndex, writerIndex - readerIndex); } else { // 如果readerIndex大于等于新的capacity,说明没有数据需要复制到新缓冲区,直接将readerIndex和writerIndex设置为newCapacity即可 setIndex(newCapacity, newCapacity); } setArray(newArray); } return this; } private void setArray(byte[] initialArray) { array = initialArray; tmpNioBuf = null; } 3. 字节数组复制
在AbstractByteBuf中的读写操作中,具体的读写操作由子类实现,我们来看一下 UnpooledHeapByteBuf 是怎么做的。
在写操作中,首先检查入参,然后将数据 copy 至 ByteBuf 的 byte 数组中。
在读操作中,也是先检查入参,然后将 ByteBuf 的 byte 数组 copy到指定的byte数组里面。
public ByteBuf setBytes(int index, byte[] src, int srcIndex, int length) { // 根据AbstractByteBuf的写操作可知,index为writerIndex checkSrcIndex(index, length, srcIndex, src.length); System.arraycopy(src, srcIndex, array, index, length); return this; } protected final void checkSrcIndex(int index, int length, int srcIndex, int srcCapacity) { checkIndex(index, length); if (srcIndex < 0 || srcIndex > srcCapacity - length) { throw new IndexOutOfBoundsException(String.format( "srcIndex: %d, length: %d (expected: range(0, %d))", srcIndex, length, srcCapacity)); } } protected final void checkIndex(int index, int fieldLength) { ensureAccessible(); if (fieldLength < 0) { throw new IllegalArgumentException("length: " + fieldLength + " (expected: >= 0)"); } // writerIndex + length > capacity,数组下表越界 if (index < 0 || index > capacity() - fieldLength) { throw new IndexOutOfBoundsException(String.format( "index: %d, length: %d (expected: range(0, %d))", index, fieldLength, capacity())); } } // 读操作时,将字节数组copy出去 public ByteBuf getBytes(int index, byte[] dst, int dstIndex, int length) { checkDstIndex(index, length, dstIndex, dst.length); System.arraycopy(array, index, dst, dstIndex, length); return this; } 4. Netty 的 ByteBuf 转换为 NIO 的 ByteNuffer
利用byte数组创建一个新的ByteBuffer,并调用slice方法,清除 discard 区域。
public ByteBuffer nioBuffer(int index, int length) { ensureAccessible(); // slice():copy一个原来的position到limit之间的有效数据,创建一个新的ByteBuffer return ByteBuffer.wrap(array, index, length).slice(); } public static ByteBuffer wrap(byte[] array, int offset, int length) { try { return new HeapByteBuffer(array, offset, length); } catch (IllegalArgumentException x) { throw new IndexOutOfBoundsException(); } } 六、UnpooledDirectByteBuf
与UnpooledHeapByteBuf不同,UnpooledDIrectByteBuf是基于堆外内存创建的。
1. 成员变量
这里跟 UnpooledHeapByteBuf 最大的不同就是,这里使用 ByteBuffer 存储数据,而 UnpooledHeapByteBuf 使用字节数组。另一个不同就是,这里的ByteBuffer使用的是NIO的DirectByteBuffer,需要自己手动释放内存。
// ByteBuf内存分配 private final ByteBufAllocator alloc; // 这里跟UnpooledHeapByteBuf不同,这里使用的是NIO的ByteBuffer存储字节数组 private ByteBuffer buffer; private ByteBuffer tmpNioBuf; private int capacity; //用于标记ByteBuffer是否释放了(这里使用堆外内存创建ByteBuffer,需要自己做垃圾回收) private boolean doNotFree;
2. 动态扩展缓冲区
这里的设计跟UnpooledHeapByteBuf是一样的,不同的是这里使用的是ByteBuffer而不是byte数组。
public ByteBuf capacity(int newCapacity) { ensureAccessible(); // 1. 校验粗人惨 if (newCapacity < 0 || newCapacity > maxCapacity()) { throw new IllegalArgumentException("newCapacity: " + newCapacity); } int readerIndex = readerIndex(); int writerIndex = writerIndex(); int oldCapacity = capacity; if (newCapacity > oldCapacity) { // 这里直接创建一个新的ByteBuffer,将老的ByteBuffer数据copy过去 ByteBuffer oldBuffer = buffer; // 创建一个DirectByteBuffer ByteBuffer newBuffer = allocateDirect(newCapacity); // 设置position和limit的值 oldBuffer.position(0).limit(oldBuffer.capacity()); newBuffer.position(0).limit(oldBuffer.capacity()); newBuffer.put(oldBuffer); newBuffer.clear(); // 替换老的ByteBuffer并释放掉老的ByteBuffer setByteBuffer(newBuffer); } else if (newCapacity < oldCapacity) { // 这里跟UnpooledHeapByteBuf处理是一样的,详细看UnpooledHeapByteBuf ByteBuffer oldBuffer = buffer; ByteBuffer newBuffer = allocateDirect(newCapacity); if (readerIndex < newCapacity) { if (writerIndex > newCapacity) { writerIndex(writerIndex = newCapacity); } oldBuffer.position(readerIndex).limit(writerIndex); newBuffer.position(readerIndex).limit(writerIndex); newBuffer.put(oldBuffer); newBuffer.clear(); } else { setIndex(newCapacity, newCapacity); } setByteBuffer(newBuffer); } return this; } // 创建DirectByteBuffer protected ByteBuffer allocateDirect(int initialCapacity) { return ByteBuffer.allocateDirect(initialCapacity); } private void setByteBuffer(ByteBuffer buffer) { ByteBuffer oldBuffer = this.buffer; if (oldBuffer != null) { if (doNotFree) { doNotFree = false; } else { // 释放oldByteBuffer freeDirect(oldBuffer); } } this.buffer = buffer; tmpNioBuf = null; capacity = buffer.remaining(); } 3. 字节数组复制
我们先看写操作的setBytes()方法,同样的,先进行参数校验,然后创建一个临时的ByteBuffer,这个ByteBuffer与 buffer 的 content 共用,往 tmpBuf 中写数据相当于往 buffer 中写数据。
public ByteBuf setBytes(int index, byte[] src, int srcIndex, int length) { // 参数校验 checkSrcIndex(index, length, srcIndex, src.length); // 创建一个临时的tmpBuf ByteBuffer tmpBuf = internalNioBuffer(); tmpBuf.clear().position(index).limit(index + length); tmpBuf.put(src, srcIndex, length); return this; } private ByteBuffer internalNioBuffer() { ByteBuffer tmpNioBuf = this.tmpNioBuf; if (tmpNioBuf == null) { // 令tempNioBuf和buffer共用同一个ByteBuffer内容,修改了tmpNioByteBuf,也等同于修改了buffer // 但是它们的position、limit都是独立的 this.tmpNioBuf = tmpNioBuf = buffer.duplicate(); } return tmpNioBuf; } 然后再来看读操作的getBytes()方法,同样的,先检查入参,然后创建出一个临时的 ByteBuffer,由这个临时的 ByteBuffer 做读操作。
public ByteBuf readBytes(byte[] dst, int dstIndex, int length) { checkReadableBytes(length); getBytes(readerIndex, dst, dstIndex, length, true); readerIndex += length; return this; } private void getBytes(int index, byte[] dst, int dstIndex, int length, boolean internal) { checkDstIndex(index, length, dstIndex, dst.length); if (dstIndex < 0 || dstIndex > dst.length - length) { throw new IndexOutOfBoundsException(String.format( "dstIndex: %d, length: %d (expected: range(0, %d))", dstIndex, length, dst.length)); } ByteBuffer tmpBuf; if (internal) { tmpBuf = internalNioBuffer(); } else { tmpBuf = buffer.duplicate(); } tmpBuf.clear().position(index).limit(index + length); tmpBuf.get(dst, dstIndex, length); } 4. Netty 的 ByteBuf 转换为 NIO 的 ByteNuffer
这里直接拿buufer的content创建一个新的ByteBuffer。
public ByteBuffer nioBuffer(int index, int length) { return ((ByteBuffer) buffer.duplicate().position(index).limit(index + length)).slice(); } public ByteBuffer duplicate() { return new DirectByteBuffer(this, this.markValue(), this.position(), this.limit(), this.capacity(), 0); } 七、PooledDirectByteBuf
PooledDirectByteBuf基于内存池实现,与UnpooledDirectByteBuf唯一的不同就是缓冲区的分配和销毁策略。
1. 创建字节缓冲区
由于采用内存池实现,所以新建实例的时候不能使用 new 创建,而是从内存池中获取,然后设置引用计数器的值。
static PooledDirectByteBuf newInstance(int maxCapacity) { PooledDirectByteBuf buf = RECYCLER.get(); buf.setRefCnt(1); buf.maxCapacity(maxCapacity); return buf; } 2. 复制新的字节缓冲区
同样的,复制新字节缓冲区时,也需要通过内存池创建一个字节缓冲区,然后执行复制操作。
public ByteBuf copy(int index, int length) { // 参数校验 checkIndex(index, length); // 从内存池中创建一个ByteBuf ByteBuf copy = alloc().directBuffer(length, maxCapacity()); // 复制操作 copy.writeBytes(this, index, length); return copy; } 八、PooledHeapByteBuf
PooledHeapByteBuf 与 PooledDirectByteBuf 不同的地方在于创建对象时使用的是byte数组而不是ByteBuffer,这里我们就不在讨论了。